02
Greedy InfoMax
Take any conventional neural network architecture. With Greedy InfoMax, we want to train it without end-to-end backpropagation. In order to do so, we remove the global loss, divide the network into separate modules (e.g. individual layers or stacks of layers) and use a separate local loss for the training of each module. Then, we block gradients from flowing in between these modules. This enforces that each module greedily optimizes its own local objective.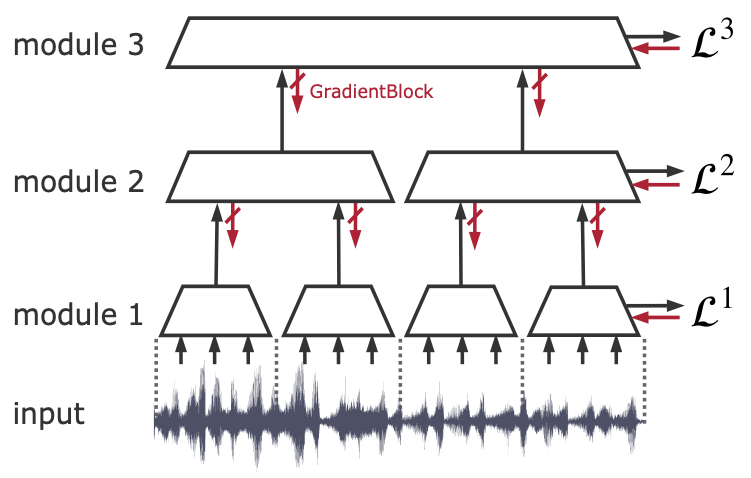
But how do we make sure that modules provide meaningful inputs to one another – even though they do not share gradients?
Contrastive Learning
Our magic trick is called contrastive learning. Recently, several papers successfully applied variants of this method in combination with end-to-end backpropagation to different tasks and domains. Have a look, for example, at Deep InfoMax by Hjelm et al. (2019), Contrastive Predictive Coding by van den Oord et al. (2018), Contrastive Multiview Coding by Tian et al. (2019), Contrastively-trained Structured World Models by Kipf et al. (2019) and Multi-View Information Bottleneck by Federici et al. (2020).In Greedy InfoMax, we contrast information from different time-steps. To understand the idea behind this variant of contrastive learning, imagine we are given a short speech sample:

Now consider two small patches from this sample, "cats" and "awe" for example. These speech patches share a lot of information with one another. For example, the identity of the speaker, the emotion that is being expressed, and (if we select patches of a smaller time-scale) also the words and phonemes that are being said. All this shared information – speaker identity, emotions, words – could potentially be helpful if we can extract it with a neural network. Thus, our goal is to train a neural network in such a way that it learns to preserve this information that is shared between temporally nearby patches.
For this, we use the InfoNCE objective developed by van den Oord et al. (2018). Essentially, this objective pairs the representations of temporally nearby patches \((z_t, z_{t+k})\), termed the positive sample, and contrasts them against random pairs \((z_t, z_j)\), termed negative samples. Thus, the positive sample could correspond to the patches "cats" and "awe" from above and the negative sample could correspond to the patch "cats" paired with any other patch that we can sample from our dataset. "Contrasting" in this setting means that the neural network has to learn to differentiate between these two types of samples, i.e. to classify them correctly.
How does this contrasting help us to train a neural network without end-to-end backpropagation?
Van den Oord et al. (2018) showed that the InfoNCE objective enforces the model to preserve the information that is shared between pairs of temporally nearby patches. Mathematically speaking, this means that the InfoNCE objective maximizes the mutual information between temporally nearby representations. In other words, the mutual information between the representations for the time-steps \(t\) and \(t+k\):
\[\text{max } I(z_t, z_{t+k})\]
Intuitively, we can draw the connection between contrastive learning and the mutual information by looking at the definition of the mutual information as the KL divergence between the joint distribution of \(z_t\) and \(z_{t+k}\) and the product of their marginals:\[I(z_t, z_{t+k}) = KL(P_{z_t, z_{t+k}} || P_{z_t} P_{z_{t+k}}) \]
In this context, our positive sample \((z_t, z_{t+k})\) can be seen as a sample from the joint distribution \(P_{z_t, z_{t+k}}\) since \(z_t\) and \(z_{t+k}\) are drawn together. The negative sample \((z_t, z_j)\), on the other hand, can be seen as a sample from the product of the marginal distributions \(P_{z_t} P_{z_{t+k}}\) since \(z_t\) and \(z_j\) are drawn irrespective of one another. Since the InfoNCE objective pushes these two samples to be as distinguishable as possible (such that it can classify them correctly), this implicitly increases the KL divergence and thus the mutual information between \(z_t\) and \(z_{t+k}\).Since we use the InfoNCE loss for the training of each module (i.e. each individually trained subpart of the neural network) in Greedy InfoMax, all of the above also applies to the representations that these modules create. Thus, in the Greedy InfoMax setting, each module \(m\) maximizes the mutual information between the representations that it creates for time-steps \(t\) and \(t+k\):
\[\text{max } I(z_t^m, z_{t+k}^m)\]
This is highly relevant for the Greedy InfoMax setting, since maximizing the mutual information between temporally nearby representations in turn also maximizes the mutual information between temporally nearby inputs and outputs of each module. In other words, using the InfoNCE objective, we also maximize the mutual information between \(z^{m-1}_{t+k}\), the input to module \(m\) at timestep \(t+k\) and \(z_{t}^m\), the output at timestep \(t\) (hover here to see the underlying intuition):\[I(z_t^m, z_{t+k}^m) \leq I(z_t^m, z_{t+k}^{m-1})\]
This provides us with an intuitive explanation as to why Greedy InfoMax works: By maximizing the mutual information between the input and output of each module, we enforce each module to keep as much information about its inputs as possible. Since we optimize the mutual information between different time-steps, we simultaneously discourage the modules from simply copying their inputs. Thus, the InfoNCE objective pushes modules to create useful inputs for their successors.Memory Efficiency
What do we gain from this greedy training? It allows us to train modules completely separately. This can increase the memory-efficiency – as only one module has to fit into the GPU memory at a time – and can allow us to train deeper networks on higher-dimensional input.This distributed training of individual modules is possible since Greedy Infomax allows us to remove both forward and backward locking. By default, Greedy InfoMax modules are not backward locked – they do not share gradients with one another and thus they do not need to wait for one another's gradients in the backward pass. However, in the default implementation, modules are still forward locked – they depend on their predecessor's output to do their own calculations in the forward pass. This dependency is not very strict, though, since modules do not depend on their predecessor's most recent output. Thus, we can remove the forward locking with a simple trick: by regularly (e.g. every \(x\) epochs) storing each module's output as a dataset for the next module to train on. This reduces the amount of communication needed between modules tremendously and allows us to train modules on separate devices. Ultimately, this enables Greedy InfoMax to achieve a more memory-efficient, asynchronous and distributed training.